I’ve been working on our big demo for the upcoming IOD Big Data and Analytics conference in November where we’ll highlight our Smart Cloud Analytics portfolio and ran into what’s likely a common challenge in many client environments.
We include the right to use the IBM Tivoli Log File Agent (LFA) and I was happily going down the path to install the LFA on some remote systems. All was fine until I came to a system that the LFA installer complained about not having enough disk space. I started the normal tasks of looking for big files, tarballs, etc. to whack and was able to do that some, but whatever was installed wasn’t budging and / was 100% full. Wherever I attempted to install the LFA where space was available it still complained as it was checking /tmp for space.
So, what am I to do? I thought about using the SCALA local LFA and trying out the remote SSH pull method but then I recalled a recent client request to show a simple approach for sending a log file from a remote system as if they were running a tail -F on that remote system and sending the log to SCALA. In their case, they didn’t want burden their end user with having any requisite knowledge of the LFA, how to install or configure it. Makes sense to me.
So, with a little Google-foo I can show you how to use netcat to execute a tail -F on a remote system file and stream that to the SCALA system where netcat is listening and creates a local copy of that remote system file which is picked up for indexing in SCALA.
Notes:
- Be aware of your corporate security policies!
- The contents of the file to be streamed across the network are not encrypted. (there are variants of netcat that support ssl, encryption techniques, stunnel, etc.)
- There are other methods that could be used to copy a file from one system to another in a batch mode that are secure. (e.g via ssh)
- I’m using a RedHat and SLES system here. I used ‘nc’ on RedHat (nc v1.84) and ‘netcat’ on SUSE (netcat v1.10). I didn’t spent any time investigating versions or differences.
- There are a few different timeout options that look interesting depending on your scenario.
What we’re Building
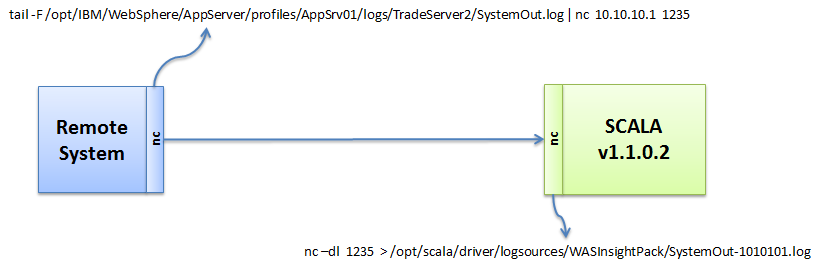
In this common log shipping and log analysis scenario, I have a WebSphere Application Server (WAS) on a remote system and it’s writing to a SystemOut.log file in a common location. I want to stream the log records from that WAS SystemOut log to the SCALA server for indexing enabling search and custom app visualization.
Getting Started
Verify that you have netcat installed on each system. Simply type ‘netcat’ or ‘nc’ to get a response. If not, find a suitable netcat|nc package for your OS.
SCALA System Side
On the SCALA server side we’re using netcat in a listener mode on a specified port. We start netcat in listen mode by using the –l option. Also in this case, we’re going to start ‘nc’ using the –d option so we can send the command to the background and ignore anything on STDIN. Remember, the port in use needs to be higher than 1024.
The power of netcat comes next when we redirect the output received from listening on the specified port and write that to a file on the SCALA system. In this case, we’re conveniently creating and writing to the log in the [SCALAHOME]/logsources/WASInsightPack/ directory so it’s automatically picked up by the local SCALA LFA and indexed by SCALA.
The command we’ll execute looks like this: (change to fit your environment)
nc –dl 1235 > /opt/scala/driver/logsources/WASInsightPack/SystemOut-165.log &
Remote System Side
One the remote system, identify the log file of interest. In our case, we’re using the standard SystemOut.log for the WAS server. On this system we’re going to execute the tail –F command on that file and pipe it into the ‘nc’ command for sending over the network. We use the –F flag for tail so it follows any logfile that gets rolled over. You could just as easy use ‘cat’ to send the entire logfile over at that point in time.
This command is piped into the netcat command ‘nc’. We’re specifying the remote SCALA v1102 system IP address 10.10.10.1 and the port we’ll be using in the netcat command issued on the SCALA server as 1235. We’ll send this to the background so it runs all the time. We are tailing a file after all!
The command we’ll execute looks like this: (change to fit your environment)
tail -F /opt/IBM/WebSphere/AppServer/profiles/AppSrv01/logs/TradeServer2/SystemOut.log | nc 10.10.10.1 1235 &
Creating a SCALA Logsource
Before we start up our netcat connections, let’s get a new SCALA log source defined so we’re ready for indexing from the start. Within the SCALA Administrative GUI, create a new logsource for the file. As we’re running netcat on the SCALA server, we’ll just use the local SCALA hostname and the full path and log file name in our log source definition. In our case we’ll use the standard WebSphere SystemOut source type and collection, but you’ll need to choose the appropriate ones for your log type.
Starting up Netcat
Start the netcat listener on the SCALA server first:
nc –dl 1235 > /opt/scala/driver/logsources/WASInsightPack/SystemOut-165.log &
Next, start the netcat client on the remote system:
tail -F /opt/IBM/WebSphere/AppServer/profiles/AppSrv01/logs/TradeServer2/SystemOut.log | nc 10.10.10.1 1235 &
To verify things are working, tail the file you’re creating on the SCALA server side as well as run some queries in the SCALA GUI for the log source you created.