To catch up on this series, start back here.
To catch up on this series, start back here.
We started with a simple deployment planning activity – get some servers built so we can get the necessary software installed and then and start hacking some configurations together to allow sample data to be collected and indexed and some simple searches and visualizations from that data to be available. Enter fun activity #1 – SoftLayer and associated VPNs. I would do anything for some way to stay logged into my SoftLayer VPN for longer than a day! Nothing pains me more than having 20 more more putty sessions up and then getting kicked off the VPN when the 24 hour timer ends. Please tell me how I can change this behavior or have some magical way to reconnect the VPN and all those putty sessions!
My partner Hao on the Dev/Ops team sent me some sample logs from a handful of Cloud Foundry (CF) components including the Cloud Controller and DEA components. Turns out each CF component type and end point system (CCI – SoftLayer Cloud Computing Instance) could have upwards of 10-20 different log types. I started out as I do with any project like this and began to immerse myself in the log samples. Before I was asked to start, Hao started kicking the tires on our Log Analysis solution on his own and hit some of the fundamental challenges in this space in terms of how to get logs in. He specifically called out logs that were wrapped in JSON, logs with timestamps in Epoch format, logs without timestamps, etc. as a few of his key challenges.
I think most of us in this space always start out in a common way – find the timestamps, find the message boundaries, find the unique message patterns that might exist within each log type and then think about what meaningful data should be extracted from each log type to enable problem isolation and resolution activities. I talk to clients about taking an approach for finding a sweet spot in their log analysis architecture between simple consolidation and archival of everything, to enabling everything for search to gaining high value insights from log data. Just because you have all kinds of logs doesn’t mean you must send them all into your log solution or invest a lot of time trying to parse and annotate every possible log message into unique and detailed fields. Finding the right balance of effort put into integration, parsing and annotation of logs, frequency of use and the value to the primary persona (Dev/Ops, IT Ops, App/Dev, etc.) are all dimensions and trade offs to consider before starting to boil the ocean. Simple indexing and search can go a long way before deep parsing and annotation is really required across all log types.
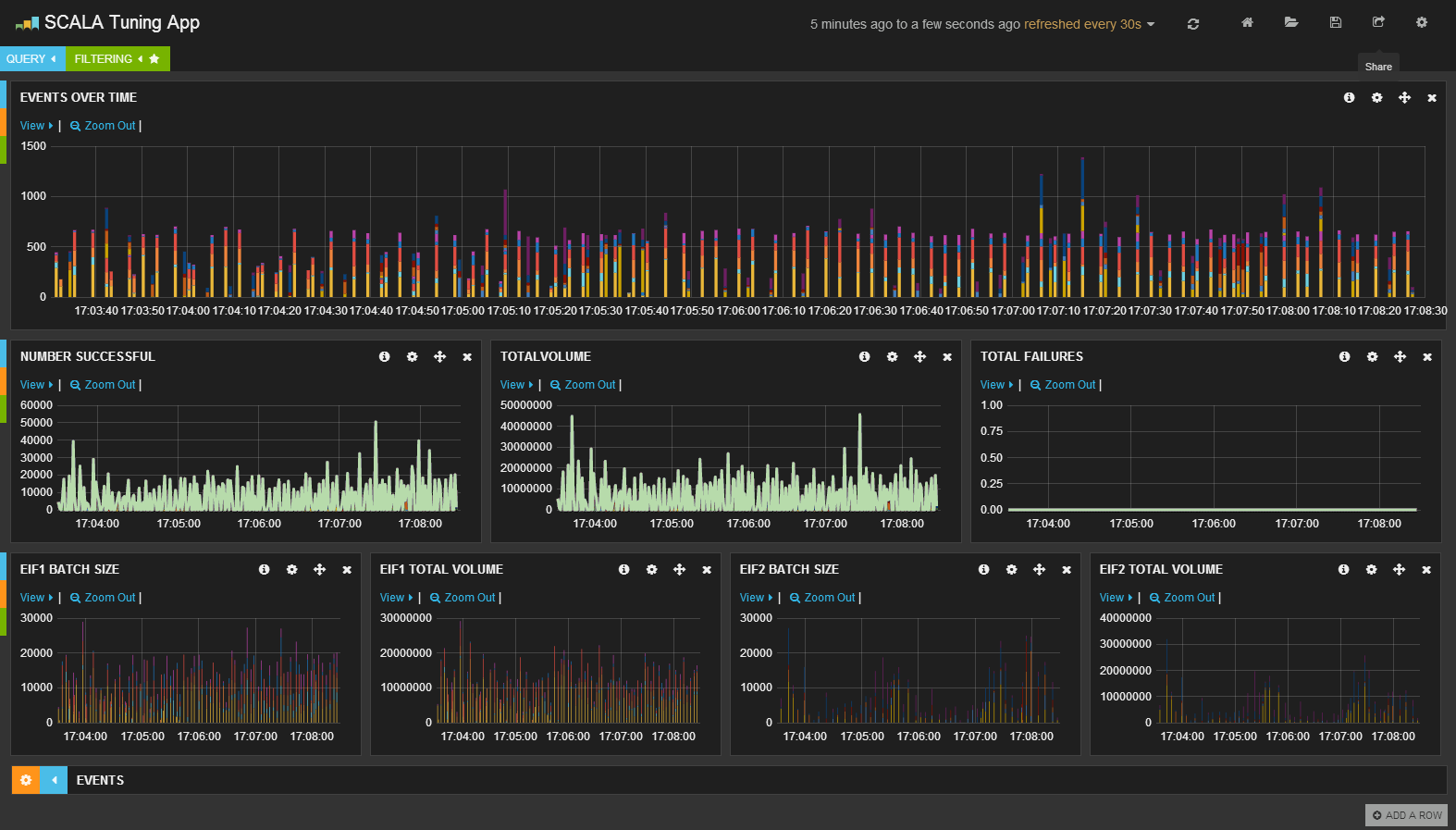
What this means to us for our first few milestones is that there are a lot of log types and we don’t have any firm requirements for what’s exactly needed yet. We don’t know which logs will prove to be most valuable to the global BlueMix Fabric Dev/Ops team. Obviously, some of these log types will be more useful in problem isolation and resolution activities. We want to bring everything in initially in a simple manner and then get that iterative feedback on which logs provide most useful insights and work on parsing and annotating those for high value search, analysis and apps. Out of two dozen unique log sources in the CF environment, we started out by taking an approach that kept things as simple as possible. We wanted to get as much data in as quick as possible so we could get feedback from the global Dev/Ops team on which log types were the most useful to them.
From the beginning of my discussions with the Dev/Ops team, we needed to keep in line with their deployment model, base images and automation approaches as much as possible. We didn’t want to deploy the Tivoli Log File Agent (actually not supported on Ubuntu anyway) or install anything else to move the log data off the end point systems. We decided to make use of the standard installation of rsyslog 4.2 (ancient!) on the Ubuntu 10.4 virtual cloud computing instances (CCIs) used within the BlueMix/CF/Softlayer environment.
We’re using the standard rsyslog imfile module to map in the 10-20 different log files per CCI into the standard rsyslog message format for shipping to a centralized rsyslog server. Each file we ship using imfile gets a functional tag assigned (eg DEA, CCNG, etc) which is useful downstream for filtering and parsing. On the centralized rsyslog server we’re using a custom template to create a simple CSV output format which we send to logstash for parsing and annotation. The point here is that we took a simple approach and normalized all of the CF logs to a standard rsyslog format which gives us a number of standardized, well formatted slots single including one slot containing the entire original message content to use downstream. I’ll spend an number of posts on rsyslog and logstash later!
Here’s an example of the typical imfile configuration:
### warden.log
$InputFileName /var/vcap/sys/log/warden/warden.log
$InputFileTag DEA_WARDEN_warden
$InputFileStateFile stat-DEA_WARDEN_warden
$InputFileSeverity debug
$InputFileFacility local3
$InputRunFileMonitor
This is the template we use to take the incoming rsyslog stream from all of the CCIs and turn it into a simple CSV formatted message structure. In reality I could even simplify this a bit more by removing a couple of the fields I’m ultimately not indexing in the Log Analysis solution.
template(name="scalaLogFormatDSV" type="list") {
property(name="timestamp" dateFormat="rfc3339" position.from="1" position.to="19")
constant(value="Z,")
property(name="hostname")
constant(value=",")
property(name="fromhost")
constant(value=",")
property(name="syslogtag")
constant(value=",")
property(name="programname")
constant(value=",")
property(name="procid")
constant(value=",")
property(name="syslogfacility-text")
constant(value=",")
property(name="syslogseverity-text")
constant(value=",")
property(name="app-name")
constant(value=",")
property(name="msg" )
constant(value="\n")
}
This gives a simple output message format like this for each of the 24 or more log types in this environment.
2014-08-07T14:42:17Z,localhost,10.x.x.x,DEA_WARDEN_warden,DEA_WARDEN_warden,-,local3,debug,DEA_WARDEN_warden, {"timestamp":1407422537.8179543,"message":"info (took 0.065380)","log_level":"debug","source":"Warden::Container::Linux","data":{"handle":"123foobar","request":{"handle":"123foobar"},"response":{"state":"active","events":[],"host_ip":"10.x.x.x","container_ip":"10.x.x.x","container_path":"/var/vcap/data/warden/depot/123foobar","memory_stat":"#
So much like the picture in this blog post, we’ve got lots of logs in all shapes and sizes. Some are huge, some are small and we’re getting them into a uniform format (eg uniform size/length for the log truck) in preparation for getting the most value from them (eg lumber). Up next, shipping an aggregated stream to logstash for parsing these normalized messages